
With the rapid advancement in artificial intelligence and machine learning, computer vision and image recognition technologies are also being developed rapidly. Image recognition applications leverage algorithms through which they recognize and categorize images.
From successfully controlling a driverless car on a highway to performing flawless face detection for biometric access, it is all possible with astounding algorithm-powered image recognition technology. Applications with this technology are growing popular. Let's dive deep into the fascinating technology of image recognition and how it is causing an innovative shift in our society.
Human and Synthetic Neural Networks
Human beings are gifted with an amazing neural network that recognizes different sets of objects effortlessly. For example, it’s quite natural for us to differentiate between a cat and a dog. Our brains do that for us automatically; when we come across the same set of images frequently, our brains make sense of the images without us realizing it. And so, we tend to just know what objects we are seeing.
A computer may not work like a human brain at the fundamental level. The way a human brain runs its calculations is something that’s still being studied. But we have tried to replicate what it does (image recognition) based on what we do know.
Computers capture an image as an array of numerical values, and it searches for a pattern among them, be it a single image or a sequence of images. This computer perception or vision uses a certain set of image processing algorithms that differentiate between features of different objects, classifying those objects.
These objects can be in the form of an image, a sequence of images, video, live, graphic, etc. A common example of computer vision is a computer's ability to distinguish between pedestrians and vehicles on the road. The reason driverless vehicles can do this is based on their ability to categorize and filter a vast number of user-uploaded images with accuracy.
Have an amazing artificial intelligence-based idea in mind? Work with us.
What is Computer Vision and its Future?
Computer vision is a field of computer science wherein computers visualize an object and come up with an accurate output. It is a field that is closely related to artificial intelligence because it focuses on simulating human eye vision. But in reality, it is a difficult task to imitate what a human eye can do so effortlessly. That is why there are so many algorithms required to make this process as accurate as possible.
In terms of business, computer-based vision technologies like object recognition apps or photo recognition apps were at a market value of almost 12 billion USD, and this is projected to increase at a value of more than 17 billion USD, at a CAGR of 7.80% between 2018 and 2023.
The reason for this rise in computer vision popularity is due to the increasing demand for autonomous and semi-autonomous cars, image matching apps, and product recognition apps for smartphones, drones (for military purposes), etc. Another factor can be the 4.0 industry revolution that is focused on introducing more automation in manufacturing processes.
Corporations around the world are adapting to computer vision and are leveraging image recognition technology to convert and analyze data coming from visual sources. Examples of image recognition applications include analysis of medical images, identification of different objects in autonomous vehicles, facial recognition for security purposes, etc.
Image Recognition
Image recognition is a technology that, with the help of machine learning concepts and the use of different algorithms, recognizes people, objects, places, and actions in images. It is a subset of computer vision that recognizes images through a camera system to favor decision-making.
In this advanced world, where computational processing power is increasing, and new advancements are discovered in machine learning, image recognition technology is asserting its presence in every area. Image recognition has a wide range of applications: augmented reality development, educational systems, medical imagery, iris recognition improvement, etc.
How it Works
A digital image is viewed in the form of a matrix of numerical values for a computer. These numerical values refer to the data generated by pixels of an image. There are pixels with different intensities, and their intensities are averaged to a single value, which itself is represented in the form of a matrix.
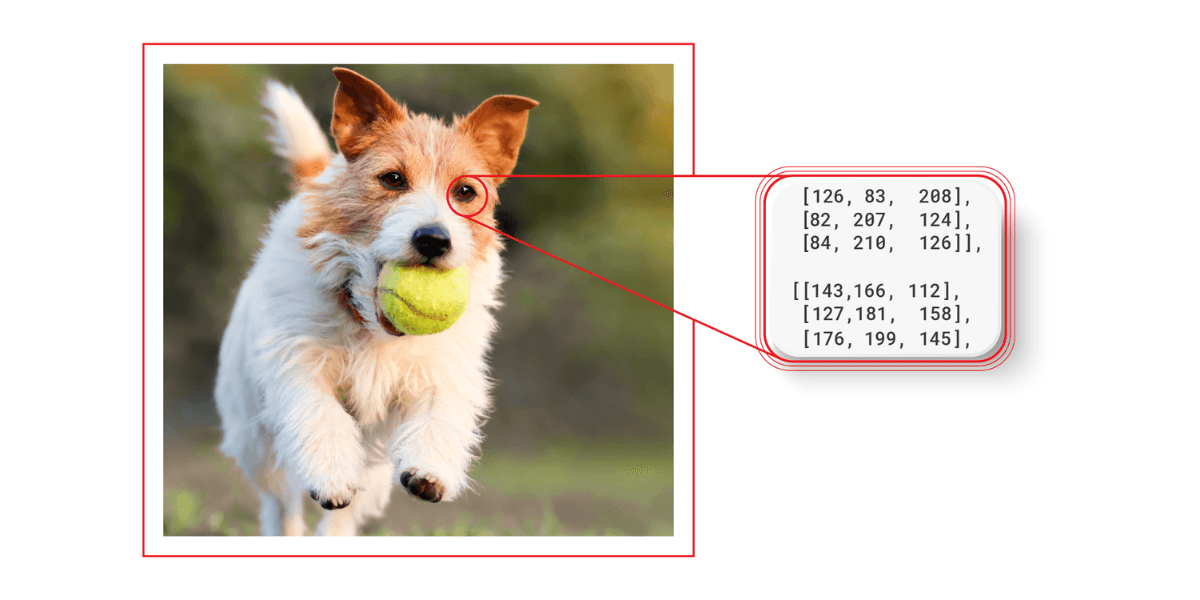
Image recognition systems are fed with information that includes the intensity of the pixels and their location within an image. This information is used to unearth a relationship or a pattern as they keep getting visuals as a part of their learning process. When the learning process is complete, system performance is validated across test data.
For improving accuracy and efficiency in an image recognition system, intermittent weights are modified in neural networks. Some of the most commonly used algorithms for image recognition are Fast R-CNN, Single Shot Detector (SSD), YOLO (You Only Look Once), and Histogram of Oriented Gradients (HOG).
What are the Challenges it Faces?
Viewpoint Variation
Viewpoint variation refers to the phenomenon in which the entities in the image may change their alignment. The image recognition system fails to understand that irrespective of the positioning of the objects in an image, it is still that same picture with the same entities in it.
Scale Variation
Zooming in and out of an image creates a problem for the classification of the objects within an image.
Deformation
Deformation does not change the actual object. The system tends to learn from the perfect image of the object and produces inaccuracies when an object is presented in a different shape.
Intra-Class Variation
Different types of objects within the same class can be present in an image. A simple example can be of different types of chairs, like an office chair, a dining table chair, a comfy chair, etc.
Image classification systems should be equipped enough to deal with problems such as putting the same objects with different types in a particular dataset.
Occlusion
A lot of objects are likely to be neglected in an image most of the time, as another object may hinder its prominence. A simple example can be of a shaded-face photo, in which a face is partially or half obstructed by the shadow.
A system should have an algorithm with a set of data large enough to overcome this hurdle and be able to detect and classify an object.
Use of Convolutional Neural Networks in Image Recognition
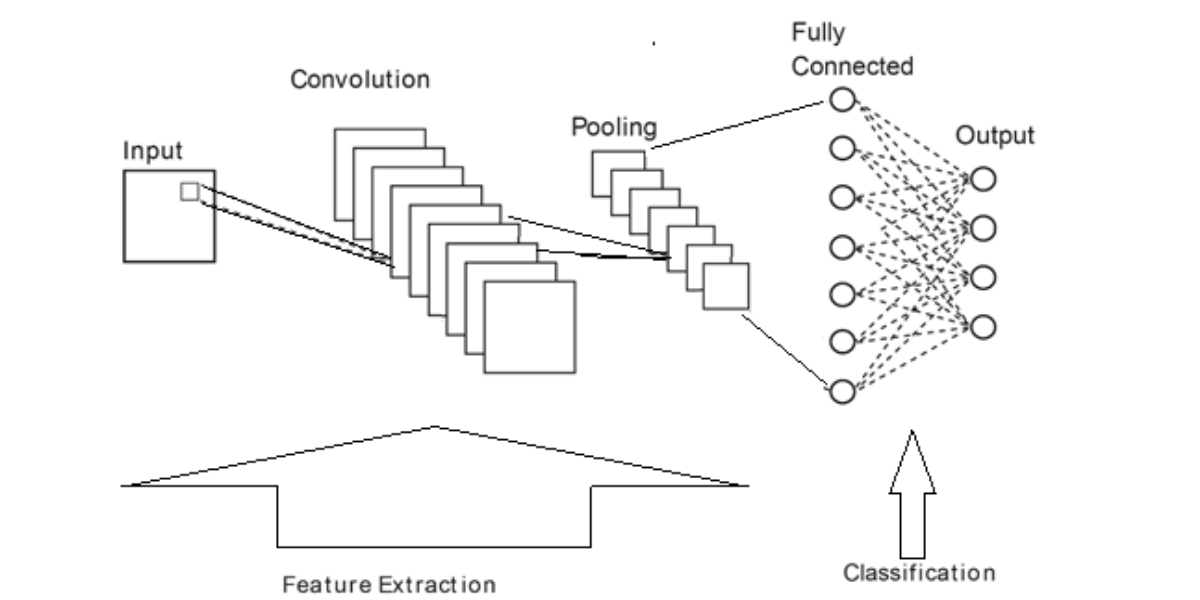
Since a regular neural network is not very efficient in solving the problems stated above, experts had to come up with a different approach. Convolutional neural networks offer solutions to obstacles in image recognition and classification. This network model is inspired by our visual cortex.
The way CNN operates is that it divides an entire picture into numerous small sets of numeric values, and it consists of a filter that is also smaller in size and consists of a matrix of numerical values. This matrix slides itself on each divided section of the image and gives a dot product of those two matrices as an output. This method is repeated until the filter has slid over the entire image.
What comes out of this process is a pattern that gives a better understanding of the image to the system and helps with classifying the objects. There may be multiple filters used for determining as many patterns as possible for better accuracy of the image detection.
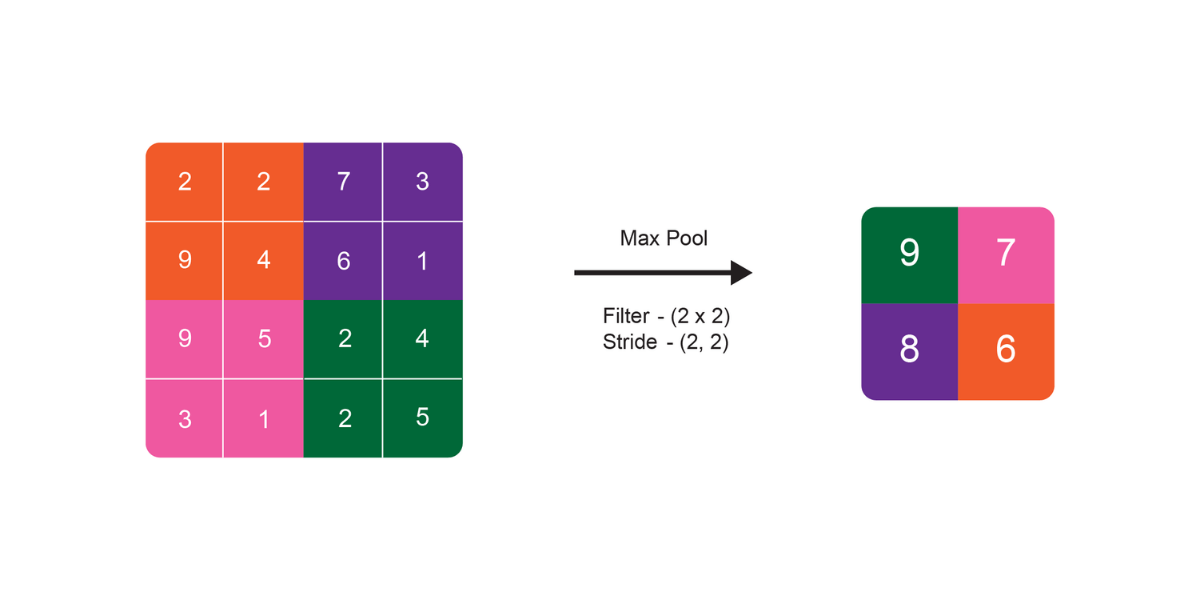
Another technique that plays a crucial part in identifying the objects is max pooling. It reduces the size of the matrix received as output from convolutional layers (filters) by extracting the maximum values from each sub-matrix. This results in a much smaller matrix. It helps in mapping out the most prominent features and gives better clarity to the previous version provided by the convolutional layer.
In the training phase, the system analyzes different levels of features and identifies and labels them as low-level, mid-level, and high-level. The low-level features include contrast, lines, and color. Mid-level features include corners and edges. And high-level features look for the class and specific forms or sections.
CNN helps reduce the computational power and makes the treatment of large images easier. CNN is sensitive to variations in an image, which results in better accuracy as compared to regular neural networks.
Its Limitation
CNN helps in overcoming a lot of image recognition issues. It can detect an object or a face in an image with an accuracy of up to 95%, which is higher than human capability (at 94%). Still, it has limitations in its utilization. The datasets with billions of parameters require high computation load power, high processing power, and memory usage. Such resources are expensive and require proper justification for use.
Uses of Image Recognition
Drones
Drones utilize this technology to detect unusual activities and ensure security to control the assets that are located in remote areas.
Manufacturing
Quality assurance of the product, an inspection of production lines, and an assessment of critical points are done on a daily basis within the establishment. These advantages in manufacturing industries are leveraged with the help of image recognition technology.
Autonomous Vehicles
Image recognition helps vehicles detect different objects on the road and possess decision-making capability. Industries can leverage mini robot technology for locating and transferring objects to different locations. This movement of products can be monitored and create a database of its history to help with preventing the products misplaced or stolen.
Military Surveillance
Image recognition technology can detect unusual activity on a military border with automatic decision-making capabilities to prevent infiltration and also save the lives of soldiers and military personnel.
